
Nowadays more and more people find themselves in the need of using a NoSQL database. Whether you are building the next Uber or Discord, or you are just realizing that you can store data in a more efficient way, NoSQL is easy to integrate in your application especially if you’re just starting out. But what if you find yourself having to migrate data heavily integrated into a legacy system?
In this article we will explore:
- One-way full data migration using EC2
- One-way full data migration using Lambda and API Gateway
- Two-way ongoing replication
- Two-way ongoing replication with the help of FIFO queues
Let’s say we have an application that uses a SQL database to store data. The application is working perfectly fine but now we want to implement a super cool feature that’s possible only with the help of NoSQL data stores. In this scenario, we now need data to be migrated and synchronized between the two data stores. In this article we are going to look into how we can use AWS-based resources for migrating data between a SQL Server database and an Atlas MongoDB database.
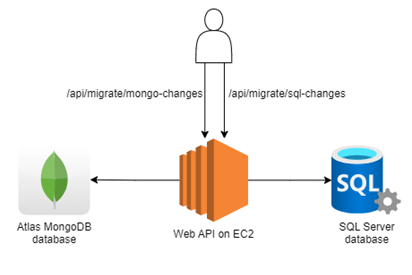
One-way full data migration using EC2
We are going to first look into the seed mechanism, because in most cases we need some of the data from SQL Server migrated before we can add new data in MongoDB. The most simplistic approach we could think of is having a virtual machine. Using AWS, we can easily spin up a VM with the help of Amazon Elastic Compute Cloud (EC2). Inside this VM, we can deploy a web API with a simple purpose – connect to both databases and through two endpoints, expose the functionality allowing one-way data migration. Since the API already has connections to both systems, we can implement the migration in both directions. This two-way seeder would be useful if at some point the data that was created on MongoDB becomes corrupted in SQL Server and a hard reset is required.
One-way full data migration using Lambda and API Gateway
Of course, the previous solution is far from ideal. If we want to have the endpoints continuously available, we must keep the VM running constantly and pay even for the time when we are not using it. Otherwise, having to turn it off and on becomes a hassle. Luckily, AWS has a handy solution for this – API Gateways with Lambdas.
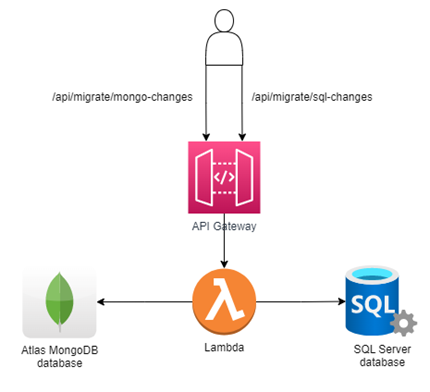
AWS Lambda is a serverless event-based compute service that allows you to run code for any type of application or backend service. Amazon API Gateway is a fully managed service that allows you to build RESTful APIs.
Now the data synchronization web API will run inside the Lambda function and the API Gateway will forward the request to the function serving as a trigger. Combining these two makes the web API available at any time, with costs pertaining only to actual usage, thanks to the serverless model.
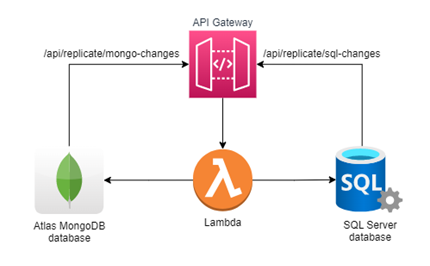
Two-way ongoing replication
Since it works in both ways, we could keep using the seeder for every migration that we need to perform, but this is an inefficient way to migrate data. For example, when we only miss one small change from one side to the other, it becomes a costly operation, therefore we will look next into how we can do ongoing replication.
Ongoing replication is a more challenging task, since in this scenario we want our databases to be able to notify the API when there are changes to be replicated and not have to rely on an inefficient polling mechanism.
One simple way to achieve this is by adding a new SQL table or a new MongoDB collection in which we insert a new row or a new document every time there is a change in a table/collection that we are interested in replicating. Let’s call both the table and the collection OutgoingChanges. The data that gets inserted in OutgoingChanges can be really simple, for example it could be formed of an identifier, a table/collection name to allow the API to identify the change and a flag to mark if the row/document was previously processed.
We can make HTTP requests from both SQL Server and Atlas MongoDB and both support insertion triggers, therefore we can set a trigger to call the API to notify that there are changes available to be replicated.
Two-way ongoing replication with the help of FIFO queues
The previous solution seems good enough at first sight, but let’s examine the following scenario. If there are five changes in a very short timespan, we would send five requests, with no control to their concurrency. We could end up with the first request processing all the changes and all the others not doing anything, or we could end up with parallel processing.
There are two ways to mitigate this problem. First is to check if there are other rows/documents that are not processed and if that is the case, to not send a notify request. This approach fails if the API is in the middle of processing OutgoingChanges when we determine if a request should be sent because the newly inserted row/document is not covered by the processing. Also, it will not send a request, so this would break our outgoing logic. The second way is by using a FIFO queue.
AWS Simple Queue Service integrates nicely with the other AWS features and it makes it easy to have the following infrastructure:
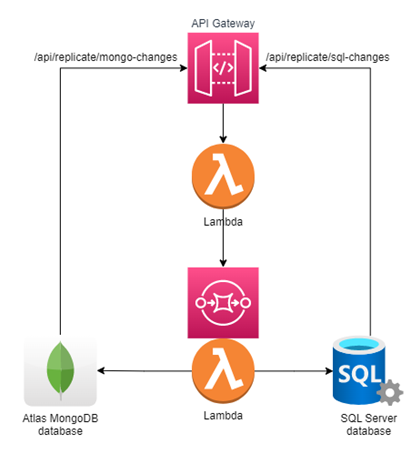
Let’s see how this solves our problem. Now the API doesn’t directly trigger the Lambda that does the processing, instead it triggers a lambda that adds a message to a FIFO queue. This is a simple, yet powerful mechanism because in AWS, FIFO queues have three properties that we can use to our advantage: message group ID, message deduplication ID and delay.
The message group ID is the tag that specifies that a message belongs to a specific message group. Messages that belong to the same message group are always processed one by one, in a strict order relative to the message group.
The message deduplication ID is the token used for deduplication of sent messages. If a message with a particular message deduplication ID is sent successfully, any messages sent with the same message deduplication ID are accepted successfully but aren’t delivered during the 5-minute deduplication interval.
Delay queues let you postpone the delivery of new messages to consumers for a number of seconds, any messages that you send to the queue remain invisible to consumers for the duration of the delay period.
Using these properties, we can define an interval in which we accept /api/replicate requests and we trigger the processing only after the specified interval. Let’s say we want this interval to be 60 seconds, that means no matter how many changes happen in a minute, we will process all of them after the interval. We can do this by setting the deduplication ID based on the time of the request and delaying the message by 60 seconds.
The IDs will be formatted as mongo-changes-yyyy-MM-dd-HH-mm and sql-changes-yyyy-MM-dd-HH-mm, so all messages that are sent within the same minute will have the same ID, resulting in only one message being sent to the consumer for each minute. If we were to not use the delay, we could end up sending a message in the 1st second of the minute and if another change would happen in the 59th second of the minute, we would not send a message because the ID would be the same.
Using the delay allows us to send only one message for the whole interval after it has passed. Since the processing could take more than one minute, we need to make sure that we don’t start a parallel process when another interval begins and that’s where message group ID is useful. We can set it to mongo-changes and sql-changes, this way we would make sure that every processing event for Mongo and SQL is handled in order.
In summary, we’ve analyzed how we can approach data migration between SQL and NoSQL data stores, shown multiple solutions and the limitations they bring. While this is far from a complete picture, I believe it is a good showcase of how we could tackle the problem using AWS-based resources, whether it’s just a simple one-way full migration or a two-way synchronization. In our practical use-case, we opted for the final, more complex approach, but keep in mind that a simpler solution could be perfectly suitable for different scenarios. Ultimately, it’s a matter of analyzing the trade-offs and the impact each decision has on the bigger picture and keeping an open eye to see when the choice you made stops being viable.

About Radu Amihăesei
Radu is a creative and passionate .NET Developer and Maxcoder, and a strong believer in learning, as well as sharing his finding with his peers. For the past years, Radu has been strongly involved in discovering the secrets of DevOps, Azure and AWS, skills which he has mastered in his work, and that are validated by his numerous certifications.


